By Adrian Bridgett | 2018-04-02
Introduction
We’ve all been in situations where releases are continuously pushed back or conversely where each release is dealing with problems caused by the previous release.
Building upon the back of excellent work by Eric Ries and my own experience, here’s my approach to tackling these issues.
Mantras
“Move fast and break things”
This was Facebook’s mantra for many years (it’s now “Move fast with stable infrastructure”). Mantras can be powerful reminders of an underlying philosophy - setting the direction of how to respond in many situations.
My mantra is: > “Plan for version 2”
… (and versions 3 and thereafter), don’t worry so much about version 1. More specifically: “Plan for v1.1, v1.2 rather than v1.0”. Several behaviours can result from this approach and some traps to avoid.
What’s wrong with v1?
The first concept is to accept that the first version will not be right. It will need tweaking/changing/fixing so the sooner you release that first version, the earlier you will find what works, what doesn’t work and what to fix. (Part of the Lean philosophy1 - highly recommended).
Why care about subsequent versions?
This isn’t to say that you shouldn’t care about that first version. There are some aspects that you absolutely should - those components that if wrong severely hinder later work and are difficult to change, therefore slowing down the release of subsequent versions.
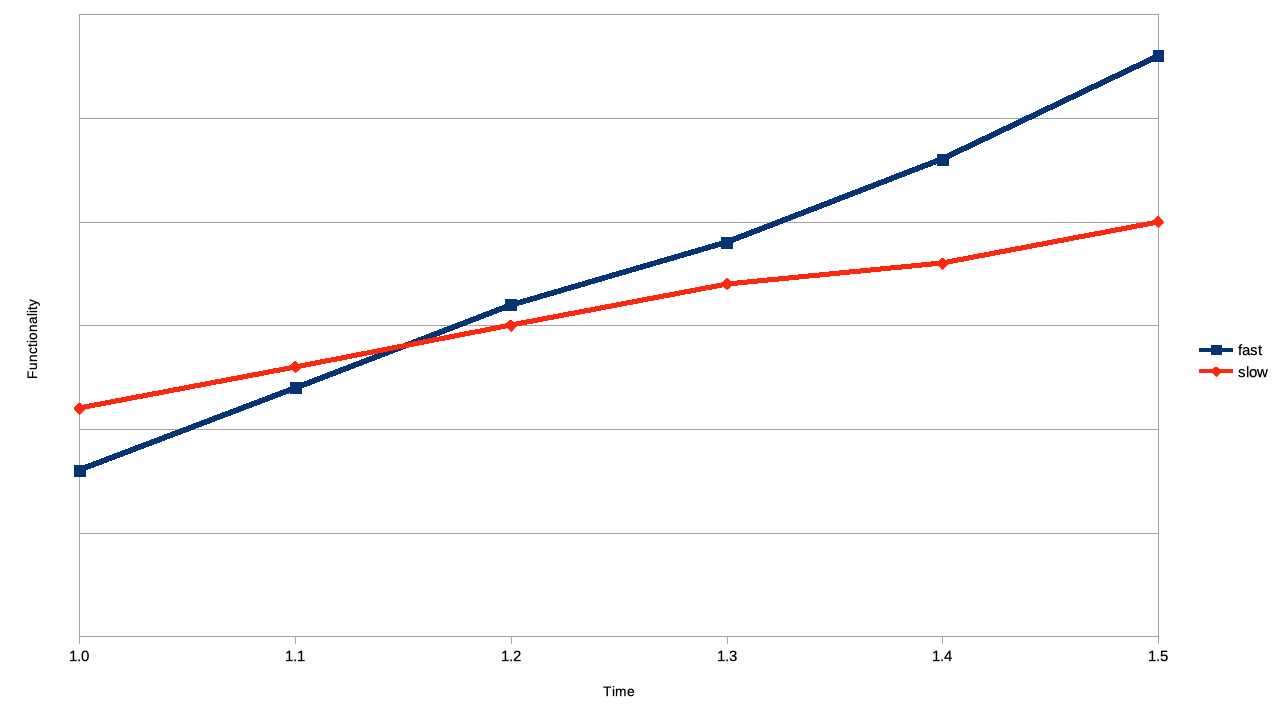
Be mindful of future velocity. Often a relatively small amount of work or forethought can save much time later - you’ve probably heard about the costs of fixing issues in production vs design (10x or even 100x isn’t unusual). Unless a product is mothballed after the first release (and if you think that’s likely, why are you working on it at all?), efficiency is often worth a little effort. A diagram is useful here - we are aiming for the blue line rather than the red line (time goes right, functionality upwards). Before long the more efficient project will be ahead of the rushed project.
Balance
How do you balance these ideas - a Minimal Viable Product without several compromising the future? One method is to defer decisions as late as you can. By releasing earlier with fewer features you are automatically moving in this direction. This needs to be done actively - i.e. a decision to decide later. The best method I’ve found to achieve this is to ask the question “if we had to release next week no matter what what’s left in?” everything else can be deferred.
There are some common areas where decisions have to be made (best to make these intentionally rather than de-facto): * deployment * migration * availability, monitoring and alerting * authentication and authorisation * testing
Deployment
While each project is unique, I strongly encourage that deployment of both current and future versions is thought about (e.g. making roll-forward and roll-back easy). In today’s agile, continuous delivery world deployment really ought to be automatable with minimal effort (and with a high rate of return - consistency, ease of development and testing), however if this isn’t possible it’s perfectly acceptable (though not ideal) for deployment to be a manual process - at least ensure that it is easy to automate.
Migration
This is probably the most important item to at consider. In many ways, it’s a bit of cheat as it could encompass everything about v2, v3… In this context however we are mainly considering items such as data storage, databases, vendor lock-in (in all forms).
For example whilst you could start with your data stored in an SQLite database, it’s likely to be something that is outgrown quite quickly. I’d encourage using a “proper” database - something like PostgreSQL for example. Separating the stateful datastore from the application helps ease deployment, scaling and in particular will make it easier to run v2 alongside v1 (possibly on a replica of the database). Using a hosted database (such as Amazon’s RDS or Google’s Cloud SQL) also reduces the time you need to spend administrating the database.
Another aspect is to plan for Forward compatibility - that is so that you can add v2 features without breaking v1.
## Availability, monitoring and alerting Do you really need multiple servers with auto-scaling for v1 of your product? Whilst not difficult, they could be deferred (not least so that you can determine the performance and failure characteristics of your application more easily).
Monitoring and alerting however are more important. Perhaps all you need is a simple health check via Pingdom or StatusCake. Even better, hopefully you have enough reuse that there you get adequate health checks and basic metrics “for free” on all new projects merely by starting from a common base project.
Authentication and authorisation
This is one of the most customer visible aspects of your product. The wrong decision now could lead to embarrassment and lost customers. The simplest approach that is often adopted is a local user database. Whilst appealing, this immediately adds the need for password reset functionality (perhaps via a support email). If you are storing passwords, you’d best do it securely (I’ve seen more than one company store them in plaintext and worse still, one even pasted them into a “description” field so that they could read out customers passwords back to them (as the application hid the password)).
Who is your customer - perhaps you can use OpenID Connect to authenticate them and thus avoid this issue? Maybe this is an internal product and you can authenticate via a directory service, Google or Github?
Testing
Most developers will spend a significant amount of time on tests - especially unit tests and integration tests. These take time initially but often pay dividends very quickly and also give peace of mind. That’s especially critical when making changes against tight deadlines as this is when mistakes are most likely to be made.
Whilst some testing can be deferred until subsequent versions, it’s a common approach to add tests before making changes to an area. In our context, that would mean that although we may be planning to refactor or extend an area in v2, we feel comfortable that we can delay writing some tests until then. Just bear in mind that you run the risk that v1 has a bug - perhaps one that caused major damage or that you must now maintain backwards compatibility with.
Exceptions
Occasionally a large leap is sometimes required - perhaps a complete re-architecture, we’ll dive into this area in the next blog post about roadmaps. To simplify - plan where needed and then tackle the plan in bite-sized chunks.
There’s one rather large caveat to all of the above. That’s the “Dead on Arrival” project - one that’s not going to go anywhere. In these cases it makes sense to take as many shortcuts as possible - no matter the consequences. Best of all - just kill the project off. The last thing you should do is to aim too high and continuously burn out the team on wasted projects - this saps morale, makes employees unhappy and they will leave.
Final thoughts
Startups have to move quickly, taking calculated risks. Large organisations are no different (although their pace may be slower, the risks are generally greater). The challenge is to have high velocity with low risk. Whilst this is often a compromise, some forethought and techniques can help both.
Overall we’re aiming to increase the velocity of future versions even if the next version itself suffers slightly as a result. These improvements should combine like compound interest so that within a few versions we’re in a far better place than we’d be otherwise. To sum up:
“Sacrifice aspects of the first version to benefit future versions”
For further reading, see Martin Fowler’s article “Is quality worth the cost?”.
References:
- The Lean Startup
- Banner image © Mike Deerkoski
_(cropped).jpg){kind=link}